I Section 1Introduction
A person's computer is not a blank slate. Bank transactions, calendar events, email threads, travel bookings, and work chats accumulate across many applications, together forming the record of a user's working and personal life. Current benchmarks for computer-use agents ignore this. Tasks run against empty desktops, generic application states, and minimally seeded databases. In most tasks, the agent is told exactly which application to open and the exact workflow to complete, with no realistic user data behind the application. An agent that can place a delivery order but cannot find which restaurant the user actually orders from every Friday has not demonstrated useful capabilities as a personal assistant.
As LLM-based assistants for personal computers move from research demos to consumer products, evaluation has to keep up: it should test whether these systems are actually personal, and whether personalization improves or regresses with each new model release.
Existing agent benchmarks span the web [WebArena][VisualWebArena][Mind2Web], full desktops [OSWorld], enterprise platforms [WorkArena], and mobile devices [AndroidWorld]. Most are simulated so that grading is deterministic and reproducible. The cost of that reproducibility is impersonality. Each application carries only the data the current task literally needs, and there is no user history behind it. Web benchmarks in particular do not evaluate any site that requires logging in or variable personal information, which rules out a large fraction of what real users ask their assistants to do.
Simulated benchmarks have traded personalization for reproducibility because no benchmark has previously seeded a coherent user identity at the scale of a user's full personal computer. MyPCBench closes this gap. A single persona specification and a deterministic multi-application generator together produce an environment that is personal, consistent across applications, and reproducible.
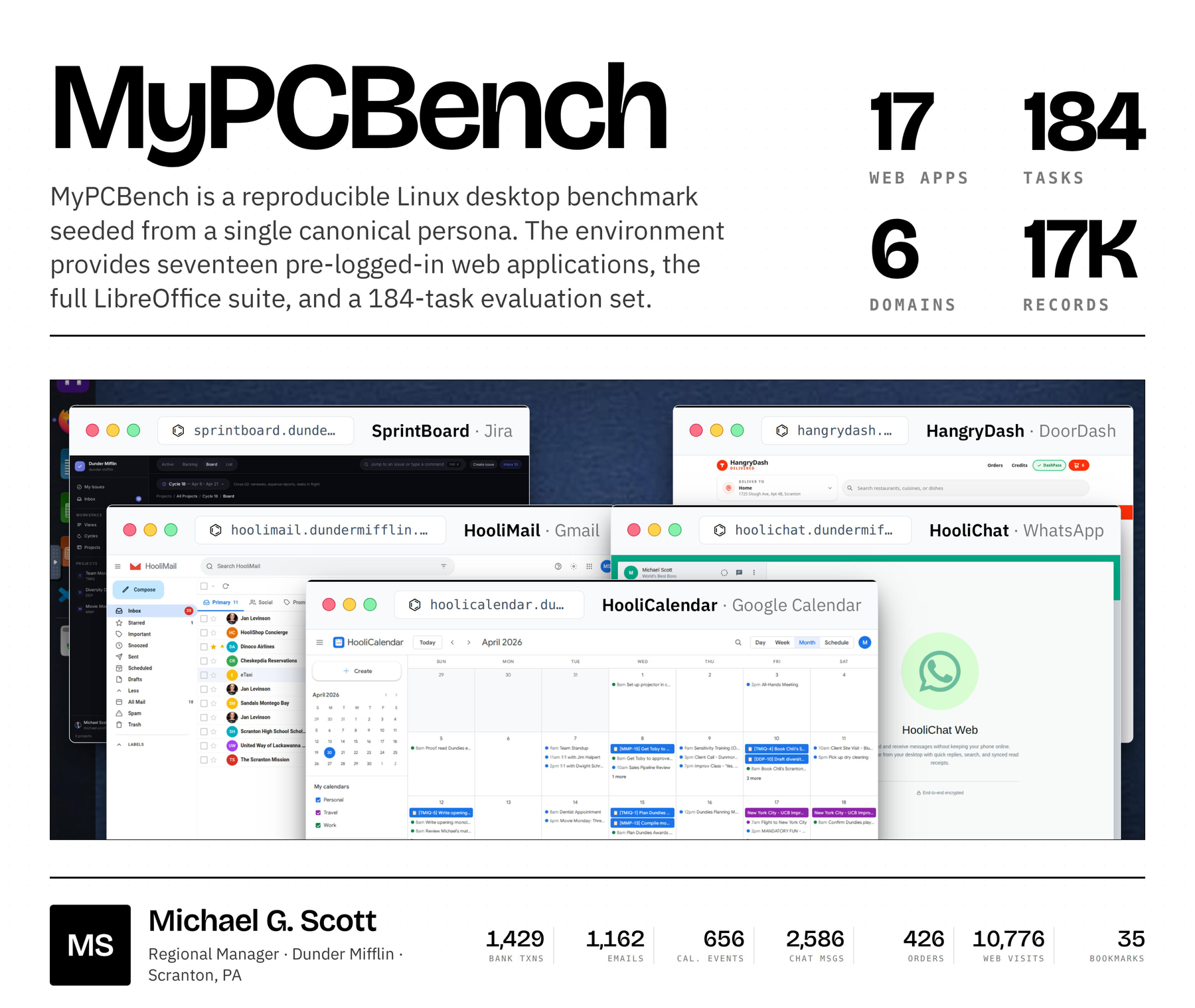
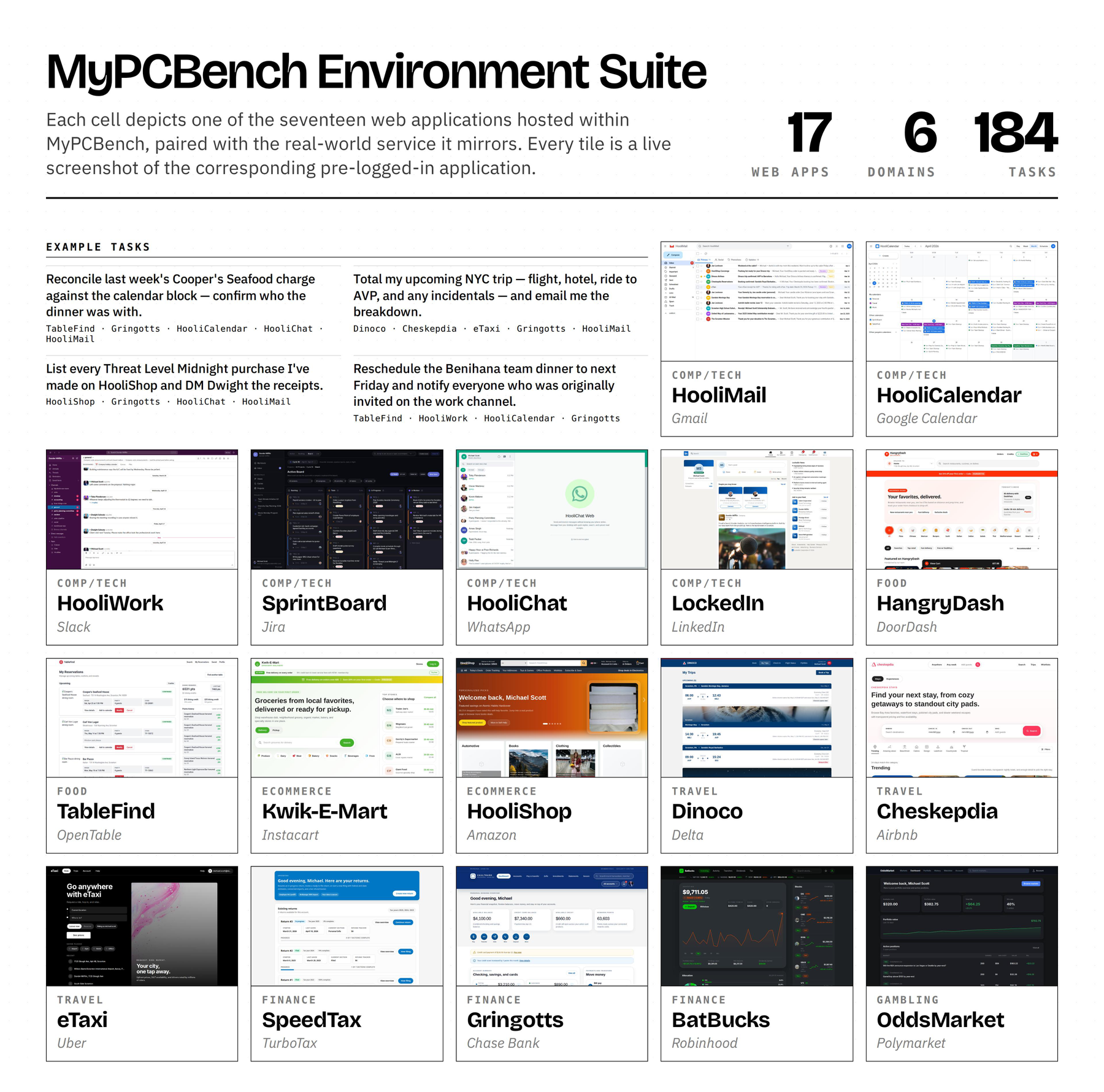
Our canonical persona is Michael Scott, the regional manager of a paper company in Scranton, Pennsylvania. Michael's desktop is seeded with 1,429 bank transactions, 1,162 emails, 656 calendar events, 2,586 chat and workplace messages, 115 rideshare requests, 300 food-delivery orders, 126 retail orders, 28 restaurant reservations, and a Firefox profile with 35 bookmarks and 10,776 page-history visits, distributed across 17 pre-logged-in web applications and the surrounding desktop stack. The 17 apps and 184 tasks were chosen by manually inspecting the OpenClaw Discord, the largest community of users running personalized LLM agents on their own desktops we are aware of, so that MyPCBench reflects the types of requests users actually issue to a personal assistant.
Our contributions are.
- A reproducible, cross-app-consistent desktop environment for evaluating personalized agents: 17 custom web apps and a full Linux desktop (Firefox, LibreOffice, file manager), deterministically populated from one persona seed and packaged as a Docker container.
- 184 tasks inspired by real OpenClaw personal-assistant requests, each with a natural-language rubric, plus an agent harness that drives the standard CUA ReAct loop against the environment and a rubric-grading LLM-as-a-judge.
- Benchmarking of six closed- and open-weight models (Claude Opus / Sonnet 4.6, GPT-5.4 / mini, Qwen 3.5 35B-A3B / 9B) under each provider's native CUA agent, with a failure taxonomy and two scaling analyses (task length and personal-data load).
Our headline finding is that even the strongest current frontier agent (Claude Opus 4.6) perfects only 55.4% of MyPCBench tasks and only 36% of tasks that span seven or more applications. GPT-5.4, Qwen 3.5 35B-A3B, and Qwen 3.5 9B all reach 0% perfect on the same 7+-app slice; the personalization regime stays wide open for future work.
III Section 3MyPCBench
3.1 · Environment
We release MyPCBench as a reproducible, open-source Linux desktop through a Docker image that runs a real QEMU/KVM Ubuntu 24.04 VM with GNOME Shell. The VM hosts seventeen pre-logged-in websites (each modelled on a real-world analogue), the full LibreOffice suite (Writer, Calc, Impress), and a Firefox profile pre-loaded with a realistic browsing history and bookmark set. Two of the web apps, HooliWork (Slack) and HooliChat (WhatsApp), are also exposed as native desktop apps, mirroring how a real user would have them open. The home directory is populated with files relating to Michael's personal and work life. MyPCBench is built around three properties for evaluating personalized agents:
(1) Cross-app consistency. Any trip, dinner, or client deal leaves correlated records in every application that would plausibly record it. Michael's Philadelphia trip generates a Cheskepdia (Airbnb) booking, two Gringotts (Chase) charges, a HooliCalendar (Google Calendar) block, two Dinoco (Delta) boarding passes, browsing history for “Radisson Blu Warwick”, three Travel-folder emails, and HooliChat (WhatsApp) messages referencing the trip. The seed pipeline writes those records together so they line up at boot, and runtime cross-app effects keep them in sync. For example, a HangryDash (DoorDash) order posts a charge to Gringotts and drops a confirmation in HooliMail (Gmail).
(2) Persona coherence. The user is a specific person, not a generic account. Friends, co-workers, routines, and preferences are interleaved characteristics of a user's data, and our environment reflects that. Because the persona is Michael Scott, frontier coding agents can draw on The Office canon to populate it with coherent, realistic data.
(3) Real-world fidelity. Each web application is a local clone with the security and reproducibility constraints of a fixed VM, but its UI, navigation, and supported flows match the real-world analogue. Every feature touched by a benchmark task was exercised end-to-end by a human author against the live VM during the QA pass.
3.2 · Environment Creation & Infrastructure
Synthetic website generation. We built the seventeen clones of real consumer products using Claude Code, each a full Next.js build rather than a static mock, following prior work on coding-agent web cloning. Gringotts supports transfers, bill pay, Zelle, and statement downloads; Dinoco Airlines generates boarding passes with QR codes; eTaxi uses OSRM for realistic routing over 700+ Scranton-area locations; TableFind exposes a reservation inventory of 3,360 slots with hold-and-release semantics. Across the canonical Michael Scott seed, the seventeen applications expose 185 distinct database tables and roughly 18,000 rows of state, of which around 17,000 are the user-facing records itemised in Figure 1.
Persona generation. The persona is specified as a JSON document covering identity, financial profile, social network, travel history, work context, routines, preferences, and recent and upcoming life events. A deterministic Python pipeline populates every part of the desktop from this spec: SQLite databases for the seventeen web apps with cross-consistent references, a Firefox profile with bookmarks, history, cookies, and form-fields, and a filesystem of meeting notes, expense reports, trip itineraries, boarding-pass PDFs, and résumé drafts.
Infrastructure. The default resource budget for a single virtual machine is 8 CPU cores and 16 GB of RAM. Boot-to-ready is about 90 seconds, and a base snapshot is captured after first boot and used to reset between tasks, avoiding state leakage. Adding personas or websites uses the same template.
IV Section 4Tasks & Evaluation Setup
4.1 · Task Suite
MyPCBench includes 184 tasks, each one inspired by a real use case or request from the OpenClaw community. To ensure the task set reflects the true distribution of requests issued to personal-computer assistants, the authors manually sieved through 2,749 anonymized and paraphrased use-cases from the OpenClaw Discord — the largest community of users running personalized LLM agents on their own desktops to our knowledge. We dropped requests that (i) were near-duplicates of an already-kept request, (ii) were infeasible inside any deterministic VM (e.g. “call my mom”), or (iii) required an app outside the seventeen we host. The remaining requests were rewritten by Claude Code so the named entities match Michael Scott's seeded data; in the same pass the coding agent generated a per-task rubric in the Odysseys [Odysseys] format. Both the rewrite and the rubric were then audited by the authors.
| Type | # Tasks | Representative instruction |
|---|---|---|
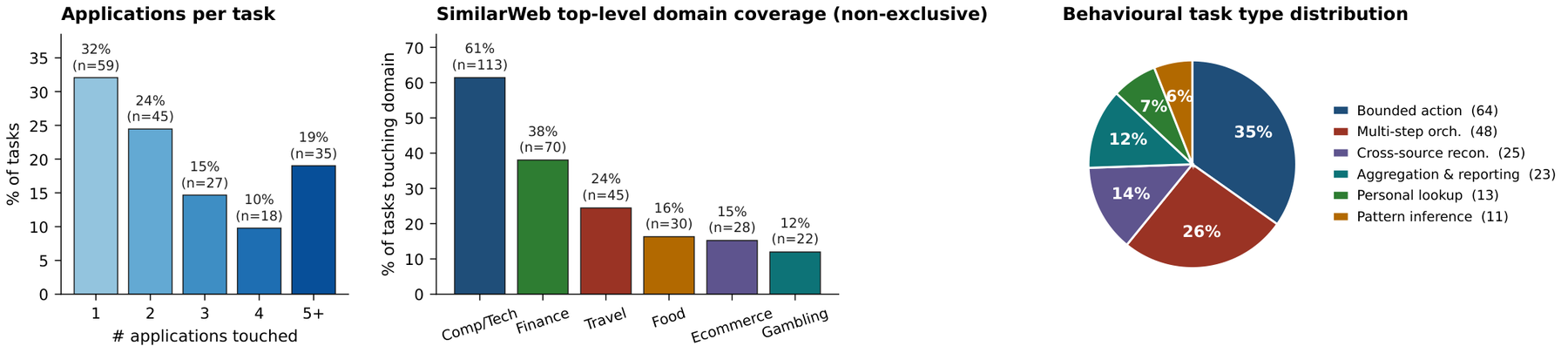
| Bounded action | 64 (35%) | “Zelle Pam a hundred bucks. She covered me last weekend. Check HooliChat first to make sure Pam Beesly is on my contacts, then put a memo on the transfer.” |
| Multi-step orchestration | 48 (26%) | “The Threat Level Midnight Fan Club has been dormant. Peek at the group chat, scroll my LockedIn contacts for Dunder Mifflin folks to recruit, draft them an invitation email, and book a watch party on my calendar for next month.” |
| Cross-source reconciliation | 25 (14%) | “I've got the Jamaica trip AND the Barbados trip booked about four weeks apart. Given my credit-card balance, can I actually afford both, or am I about to max out?” |
| Aggregation & reporting | 23 (12%) | “How much am I sending via Zelle each month, and who's getting the money? Check the most recent two complete calendar months and rank the recipients in a LibreOffice Calc spreadsheet.” |
| Personal lookup | 13 (7%) | “What's my current FlyMiles loyalty tier on Dinoco Airlines, and how many miles do I have in the bank?” |
| Pattern inference | 11 (6%) | “What do I usually tip on food delivery, in dollars and as a percent? I want to set a smart default so I'm not thinking about it every order.” |
Quality assurance. Because coding agents generate the initial task drafts and the application clones, we manually verify both. Each task was reviewed by at least two authors through a custom web interface. Reviewers ran each task end-to-end on the live VM and confirmed that (a) every named entity exists in the seeded environment, (b) the expected answer is obtainable from the environment alone, (c) each rubric criterion is individually checkable from a step-level screenshot, and (d) the task is not a near-duplicate of another in the suite. All 184 tasks survived this round.
Domain coverage. We manually map each application to a top-level SimilarWeb category by inspecting its real-world analogue, mirroring the categorization scheme used by Odysseys. The seventeen apps span six SimilarWeb top-level categories and fourteen distinct subcategories. Computers, Electronics & Technology covers HooliMail, HooliCalendar, HooliWork, SprintBoard, HooliChat, and LockedIn. Finance covers Gringotts, BatBucks, and SpeedTax. Travel & Tourism covers Dinoco Airlines, Cheskepdia, and eTaxi. Food & Drink covers HangryDash and TableFind, Ecommerce & Shopping covers HooliShop and Kwik-E-Mart, and Gambling covers OddsMarket.
Apps per task. Tasks span from one to nineteen co-touched applications, and 68% are multi-application; 40% span at least two SimilarWeb top-level categories. The multi-application regime is what tests personalization, since the agent has to reconcile data across the persona's environment rather than drive a single tool in isolation.
4.2 · Agent Harness
The harness lets us point standard CUA agents at the MyPCBench environment with as little adaptation as possible. We model MyPCBench as a partially observable Markov decision process 𝓔 = (𝒮, 𝒜, Ω, T). At each step t the agent receives an observation ot ∈ Ω from the guest VM and emits an action at ∈ 𝒜, which the harness executes through the OSWorld VNC bridge. Our harness is a thin extension of the OSWorld runner. It boots the MyPCBench Docker image, restores a fresh QEMU snapshot before every task so each run begins from an identical desktop state, attaches to the VNC display, and drives the standard agent loop until the agent emits DONE or FAIL or exhausts the step budget.
Observation space. At each step the agent receives a 1280×800 screenshot of the full Linux desktop, augmented with the running tool-call history. Screenshots are passed unmodified to vision-language model APIs.
Action space. The action space is the unmodified OSWorld pyautogui surface (click, type, key, scroll, drag, wait, screenshot, done, fail). Frontier computer-use APIs (Claude Computer Use, OpenAI CUA) each define their own action vocabularies, and we map them onto this surface through a unified translation layer (for example, Claude's computer.click becomes click, and CUA's drag path becomes drag). Anthropic's Computer Use bundle additionally ships with a native bash tool and a str_replace_based_edit_tool; we expose those through the same VNC channel when running Claude. The OpenAI CUA and Qwen CUA APIs do not expose equivalent tools; we therefore do not provide them to those agents, since adding tools they were not trained against would be both unfair and out of distribution.
4.3 · Grading
We grade each trajectory against each rubric using an LLM-as-a-Judge, following the scheme proposed by Odysseys. Every task ships with its own set of rubrics: a list of natural-language criteria {r1,…,rN} authored alongside the task and audited during the QA pass. Across the suite, rubrics range from 3 to 13 items, with a mean of 6.5 per task and 1,191 rubric items in total. The judge runs once per rubric item over the full trajectory. It is shown the task instruction for context, that one rubric item, the agent's complete action history, and every screenshot the trajectory produced.
The judge returns “Status: success” or “Status: failure” for that item. A rubric item is considered satisfied iff the judge returns “success”, and we denote this sr ∈ {0,1}. We write si for the per-task average (Σr si,r)/Ni on task i. We use gemini-3.1-flash-lite-preview as the judge model throughout.
We report three metrics per model. The rubric score is the per-task average of rubric pass rates (each rubric weighted equally) averaged across tasks; it credits partial completion. The stricter perfect rate requires every rubric in a task to pass. Trajectory Efficiency, also from Odysseys, measures how much rubric score the agent extracts per step:
where ni is the number of agent steps on task i. Trajectory Efficiency penalises agents that arrive at a correct outcome only after substantial wasted effort, and we report it scaled by 100 (percent of the rubric satisfied per agent step) for readability.
V Section 5Results
5.1 · Main Results
We evaluate six models on the full 184-task suite using each provider's native computer-use (CUA) agent. The four frontier closed-weight models are Claude Opus 4.6 and Claude Sonnet 4.6, GPT-5.4 and GPT-5.4 mini. The two open-weight models are Qwen 3.5 35B-A3B and 9B, picked for contrasting scale within the same family. Every run uses a 100-step budget and the shared persona-and-environment context, and all runs are graded by the same Gemini judge.
| Model | Perfect ↑ | Rubric score ↑ | Avg steps | Traj. Eff. ↑ |
|---|---|---|---|---|
| API · closed-weight | ||||
| Claude Opus 4.6 | 55.4 | 81.8 | 46.5 | 3.61 |
| Claude Sonnet 4.6 | 39.1 | 65.4 | 45.8 | 3.03 |
| GPT-5.4 | 23.9 | 50.5 | 41.2 | 2.26 |
| GPT-5.4 mini | 18.5 | 47.5 | 30.8 | 2.31 |
| Open weights | ||||
| Qwen 3.5 35B-A3B | 10.3 | 39.0 | 53.2 | 1.38 |
| Qwen 3.5 9B | 4.3 | 20.2 | 42.8 | 0.78 |
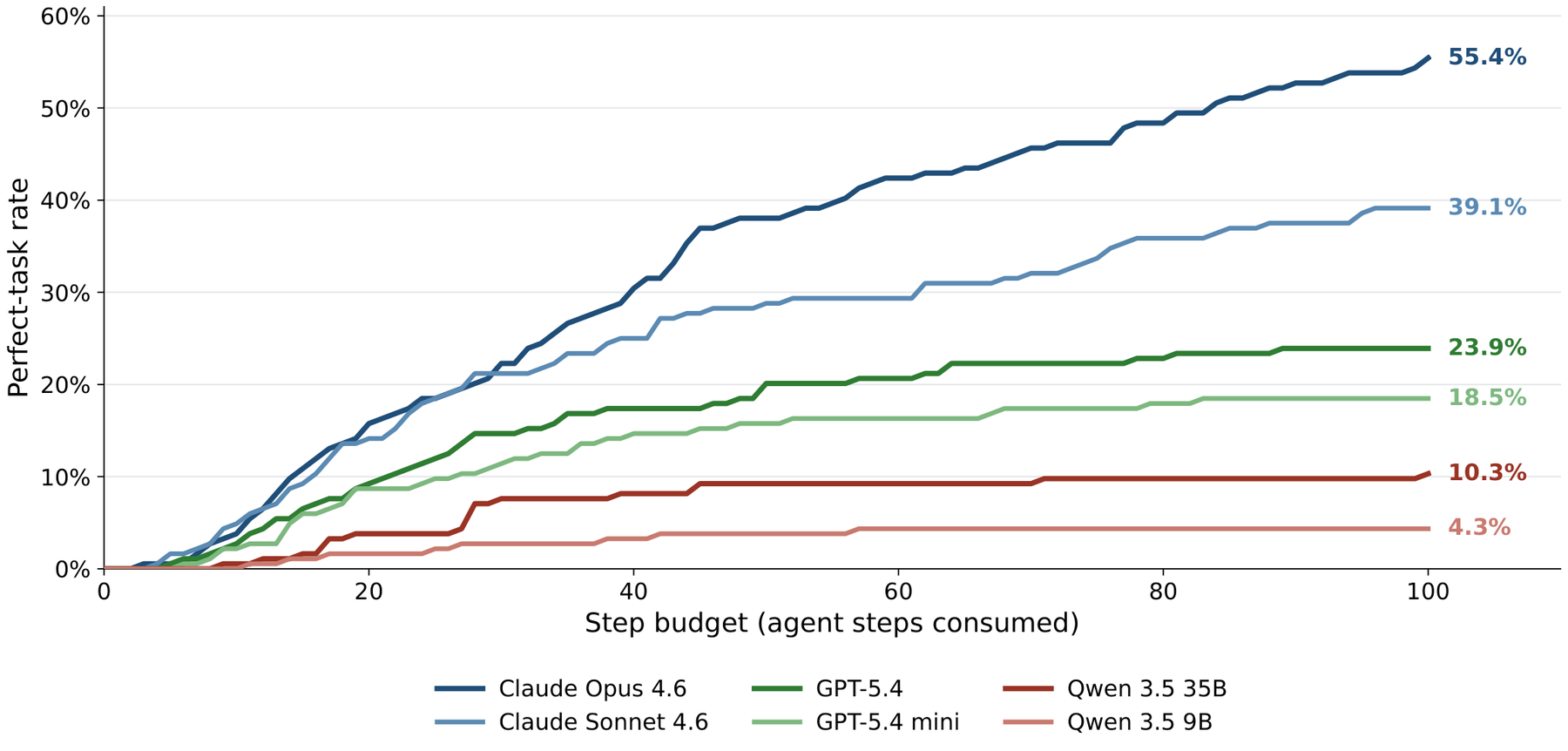
Closed-weight frontier agents lead by a wide margin. Claude Opus 4.6 reaches 55.4% perfect at 81.8% rubric score, the only model above 50% perfect and more than twice the perfect rate of any non-Claude model. Within the API tier the Opus, Sonnet, GPT-5.4, GPT-5.4 mini ordering is preserved across both metrics, with Sonnet sitting roughly halfway between Opus and the GPT-5.4 family. The open-weight Qwen 3.5 models trail every closed-weight model. Within the Qwen family the larger 35B-A3B more than doubles 9B on perfect rate (10.3% vs. 4.3%); both still fall well below GPT-5.4 mini.
Trajectory Efficiency adds a step-budget view. Opus extracts 3.61 rubric points per step, almost 5× Qwen 3.5 9B (0.78). GPT-5.4 mini consumes the fewest steps per task (30.8) but converts them less productively than the Claude tier, so its Traj. Eff. (2.31) still trails Sonnet (3.03) by 0.7 points. Average step count therefore does not by itself predict efficiency: low step counts can reflect either tight execution (Sonnet, 45.8 steps, Eff. 3.03) or premature stopping (Qwen 9B, 42.8 steps, Eff. 0.78), and the two are distinguished by the failure-mode breakdown in §6.
5.2 · Performance by Task Type
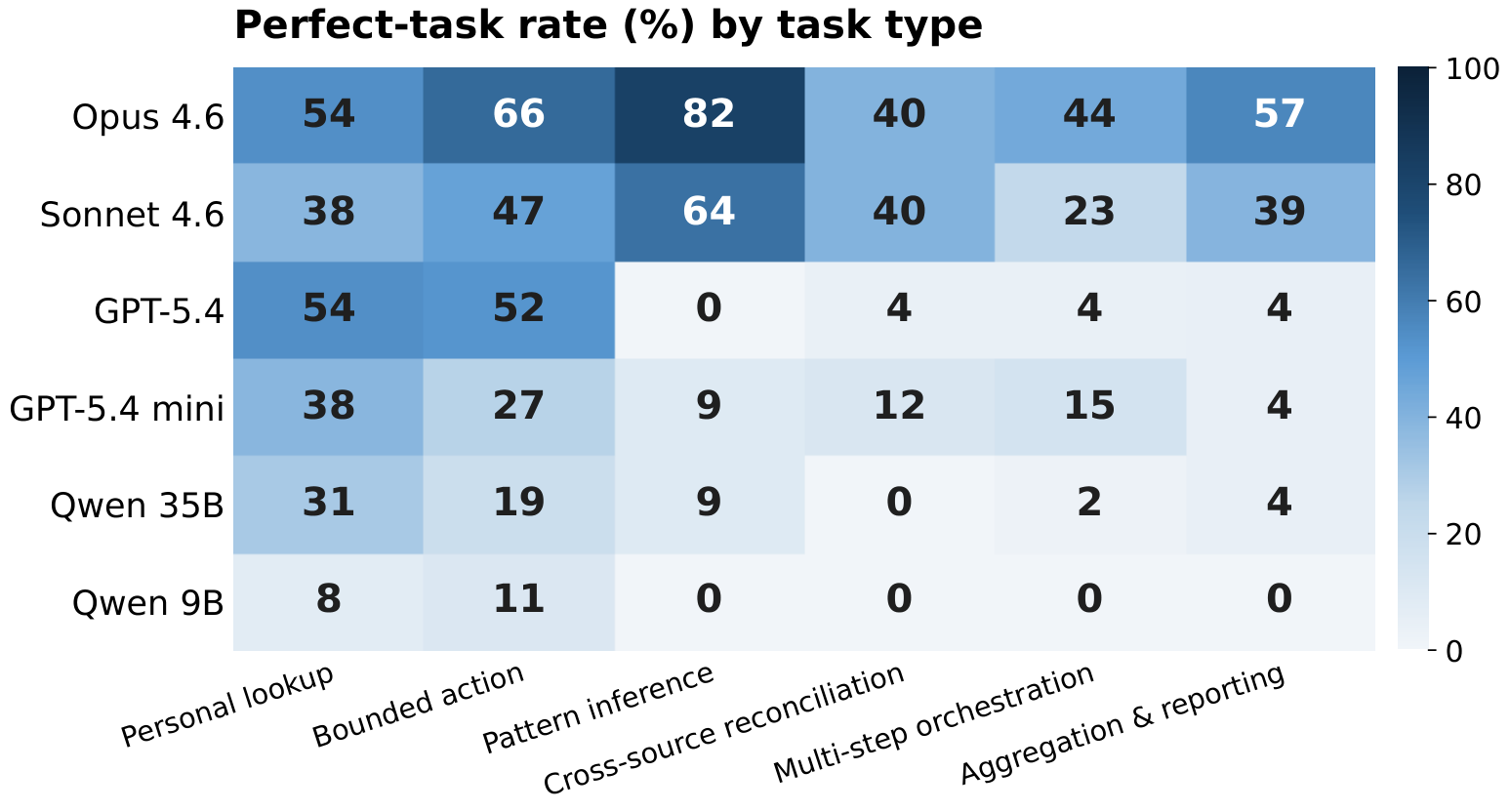
The aggregate gap in Table 2 hides large differences across the six task types. Two categories localise the gap. Bounded action and personal lookup are the only types where every model in the API tier clears 38% perfect; GPT-5.4 matches Sonnet on personal lookup (both 54%) and overtakes it on bounded action (52% vs. 47%). The remaining four categories all require either reasoning over persona history or coordinating writes across multiple apps, and the gap to Opus widens accordingly. The largest single-category gap is pattern inference, where Opus reaches 82% perfect and GPT-5.4 reaches 0% perfect on the same eleven tasks. These tasks ask the agent to infer an unstated rule from many records (“what do I usually tip?”), and the rubric only credits answers that match the rule the seeded history supports. On the three remaining analysis categories — aggregation, multi-step orchestration, cross-source reconciliation — the GPT-5.4 family and both Qwen models stay below 16% perfect, and Qwen 9B records zero perfect tasks across the three combined.
5.3 · Performance Scaling by Steps and Apps
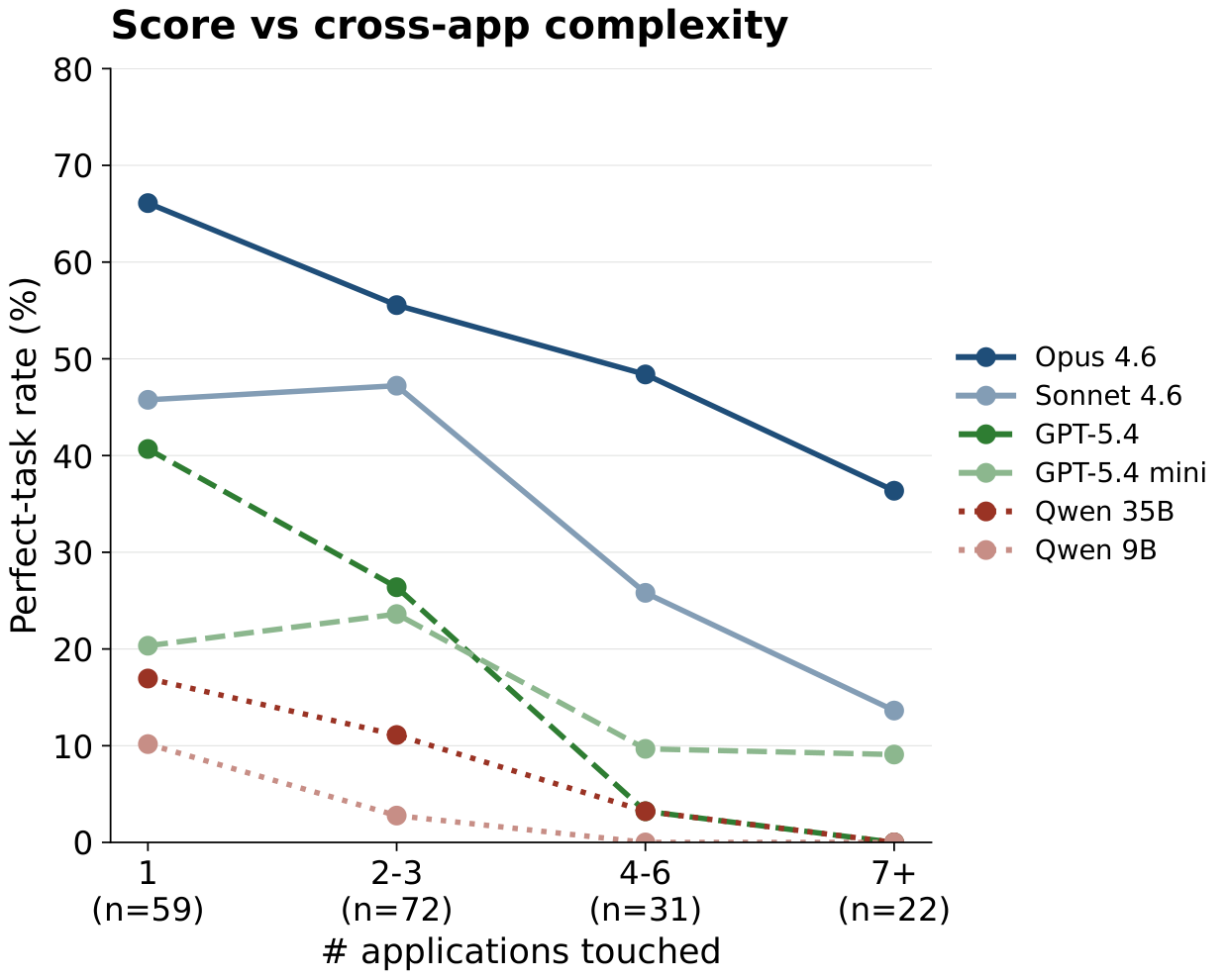
The two scaling axes are (a) the number of distinct applications a task touches and (b) the number of agent steps the trajectory consumes. Every model degrades as apps-touched grows, and the drop is sharper on perfect rate than on rubric score. From single-app to 7+-app bins, the perfect rate falls from 66% → 36% for Opus, 50% → 14% for Sonnet, 41% → 0% for GPT-5.4, and 23% → 9% for GPT-5.4 mini; the Qwen 35B model and Qwen 9B both end at 0% in the 7+-app bin.
The step axis sorts the cumulative perfect-rate curves into three regimes: Opus is still adding 7 pp between steps 60 and 100, the GPT-5.4 family flattens by step 60 (< 2 pp in the last 40 steps), and Qwen saturates by step 25. The two axes interact with the task-type findings: 68% of MyPCBench tasks span 2+ apps and 35% touch 4+, so the steep cross-app slope for the GPT and Qwen families directly produces the low perfect rates on the analysis categories above.
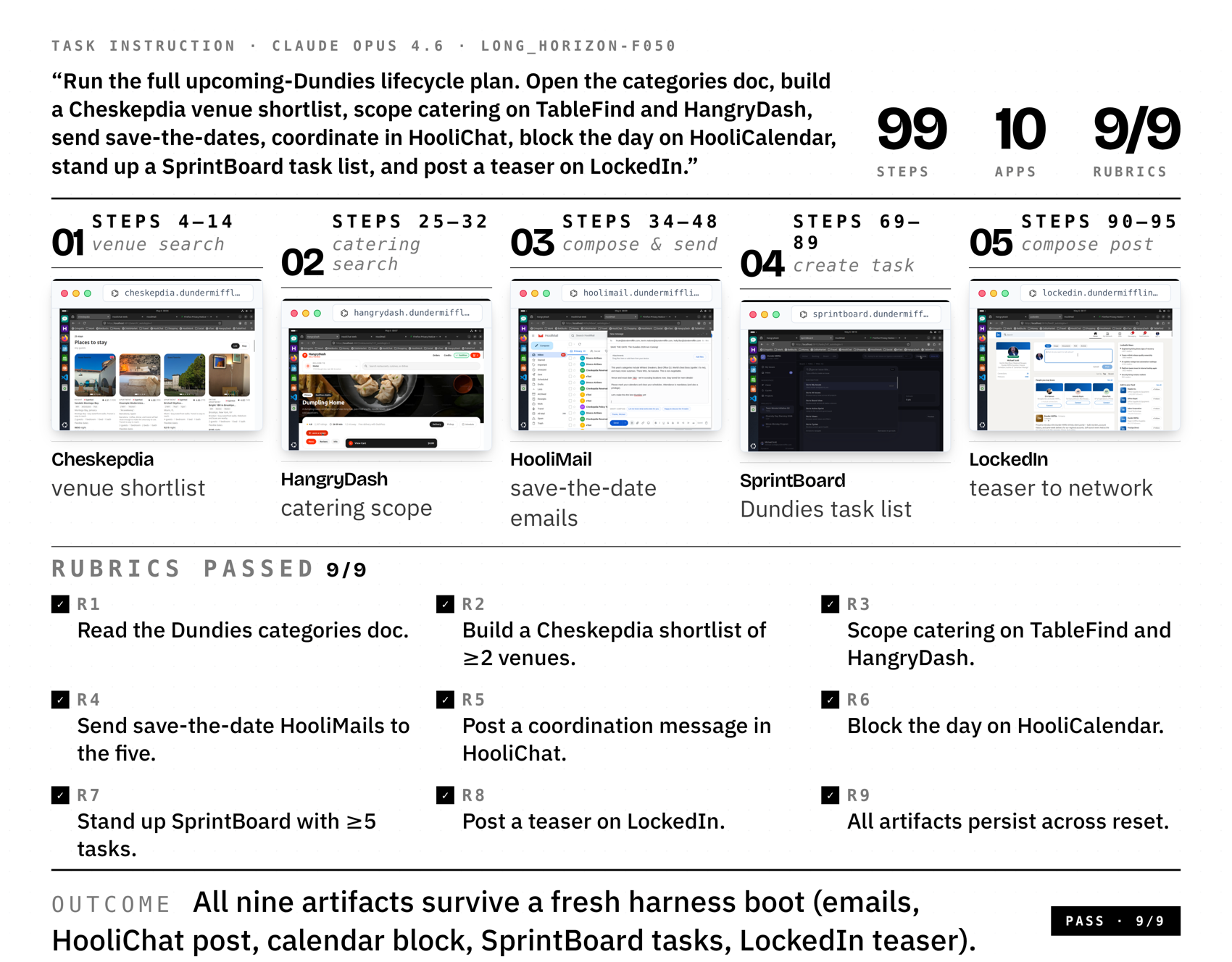
long_horizon-f050 (99 steps, 10 apps, 9/9 rubrics). Cells are real screenshots from the steps where the agent is actively driving each app; the bottom strip enumerates the nine rubric criteria the judge marked passed. Watch this trajectory interactively in the trajectory player.VI Section 6Personalization-Specific Failures
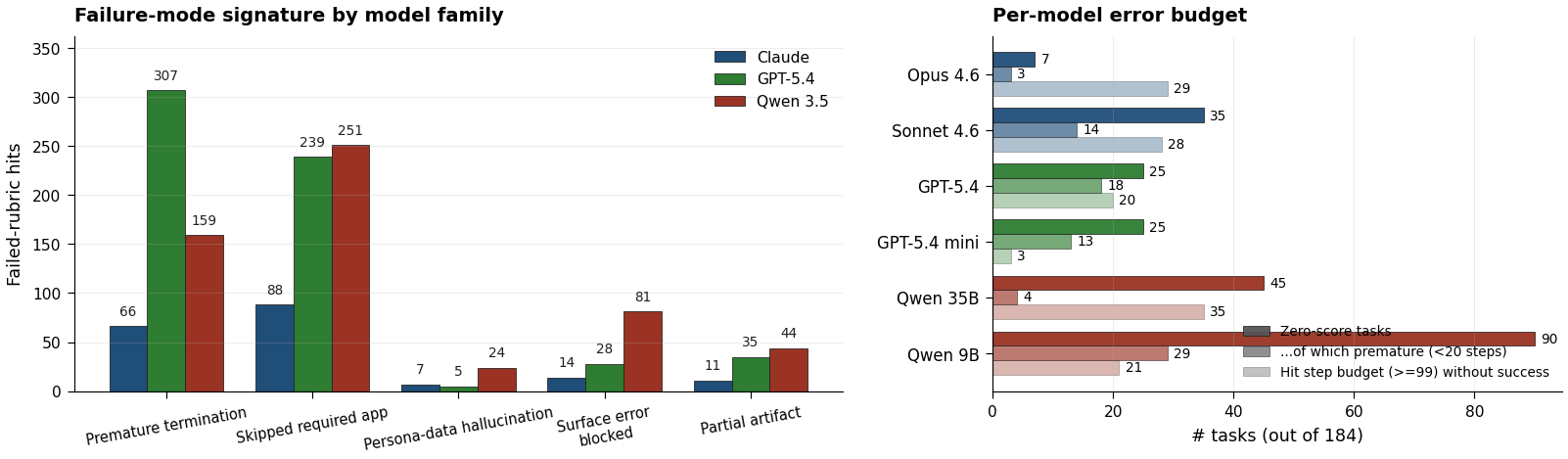
We read every failed-rubric judge explanation and tagged it with up to five categories: skipped required app, premature DONE, surface error as terminal, partial artifact, and hallucinated persona data. Skipped required apps (578 hits) and premature DONE (532) account for most of the loss; surface-error abandonment (123), partial artifact (90), and hallucinated persona data (36) follow.
The three model families concentrate in different modes: GPT in premature DONE (307 of 532 hits), Qwen in persona-data hallucination (24 of 36), and Claude in console-script shortcuts that hit app REST endpoints with its native bash tool instead of driving the visible UI. Mean step count on zero-score trajectories splits the families the same way: GPT-5.4 (17.7), GPT-5.4 mini (19.7), and Sonnet (29.7) abandon early, while Opus (52.1), Qwen 35B (52.6), and Qwen 9B (39.2) keep going until they hit the step budget.
VII Section 7Conclusion
MyPCBench seeds the empty desktop of computer-use evaluation with a coherent persona: 17 cross-consistent web apps, 17,000 personal records, and 184 tasks inspired by OpenClaw use cases. Claude Opus 4.6 leads at 55.4% perfect. We release the environment, tasks, harness, and judge for MyPCBench. We hope MyPCBench serves as a shift towards evaluating personalized computer-use agents and provides a baseline for identifying and improving the performance of frontier agents as truly personal assistants.
References
- OpenClaw Community. Personalized computer-use agents Discord. 2,749 anonymized requests, ongoing.
- Anthropic. Claude CoWork. 2026.
- Zhou et al. WebArena: A Realistic Web Environment for Building Autonomous Agents. ICLR 2024.
- Koh et al. VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks. ACL 2024.
- Deng et al. Mind2Web: Towards a Generalist Agent for the Web. NeurIPS 2023.
- He et al. WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. 2024.
- Xie et al. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. NeurIPS 2024.
- Bonatti et al. Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale. 2024.
- Yang et al. MacOSWorld: Multilingual Interactive Benchmark for GUI Agents on macOS. 2025.
- Li et al. ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Screens. 2025.
- Kapoor et al. OmniAct: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web. 2024.
- Xu et al. TheAgentCompany: Benchmarking LLM Agents on Consequential Real-World Tasks. 2025.
- Drouin et al. WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks? ICML 2024.
- Park et al. Generative Agents: Interactive Simulacra of Human Behavior. UIST 2023.
- Rawles et al. AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents. 2024.
- Liu et al. Reinforcement Learning on Web Interfaces using Workflow-Guided Exploration. ICLR 2018.
- Yao et al. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents. NeurIPS 2022.
- Jang et al. Odysseys: Benchmarking Web Agents under a Rubric-Based LLM Judge. 2026.
Cite
If MyPCBench is useful in your research, please cite the paper.
@misc{jang2026mypcbench,
title = {{MyPCBench}: A Benchmark for Personally Intelligent Computer-Use Agents},
author = {Jang, Lawrence Keunho and Jang, Andrew Keunwoo and Koh, Jing Yu and Salakhutdinov, Ruslan},
year = {2026}
}