1,429
Bank txns
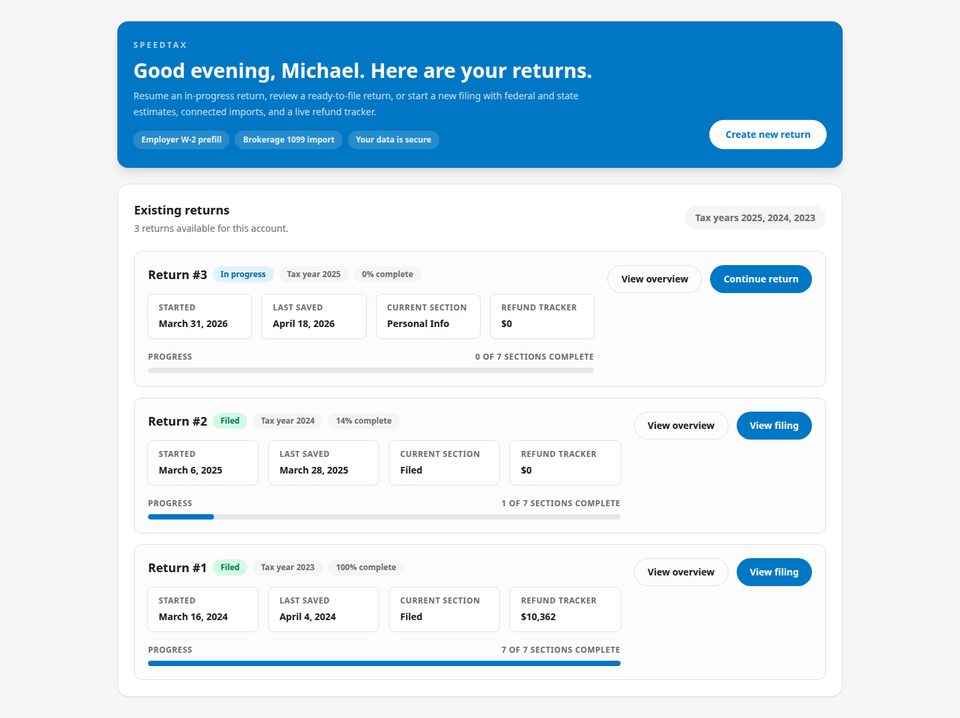
A reproducible Linux-desktop benchmark for personally intelligent computer-use agents. The environment is seeded end-to-end from one canonical persona across 17 cross-consistent web applications and roughly 17,000 personal records, and 184 tasks are graded by a per-rubric LLM judge.
Current benchmarks for computer-use agents evaluate models in impersonal environments, leaving a gap between evaluation and deployment as personal assistants are expected to work across a user's whole digital life. MyPCBench is a reproducible Linux-desktop benchmark seeded end-to-end with one user's identity, history, and logged-in accounts, so the same agent loops OSWorld-style benchmarks already use can finally be pointed at tasks that require knowing who the user is.
Web benchmarks exclude any site that requires logging in or variable personal information, ruling out a large fraction of what real users ask their assistants to do. Desktop benchmarks seed only what the task literally needs. MyPCBench pins a single user identity — Michael Scott — and spans the consumer-application surface that personal computers actually run: banking, travel, food delivery, calendar, messaging.
184 tasks rewritten from 2,749 anonymized requests collected from the OpenClaw Discord, with named entities re-aligned to the persona's seeded data.
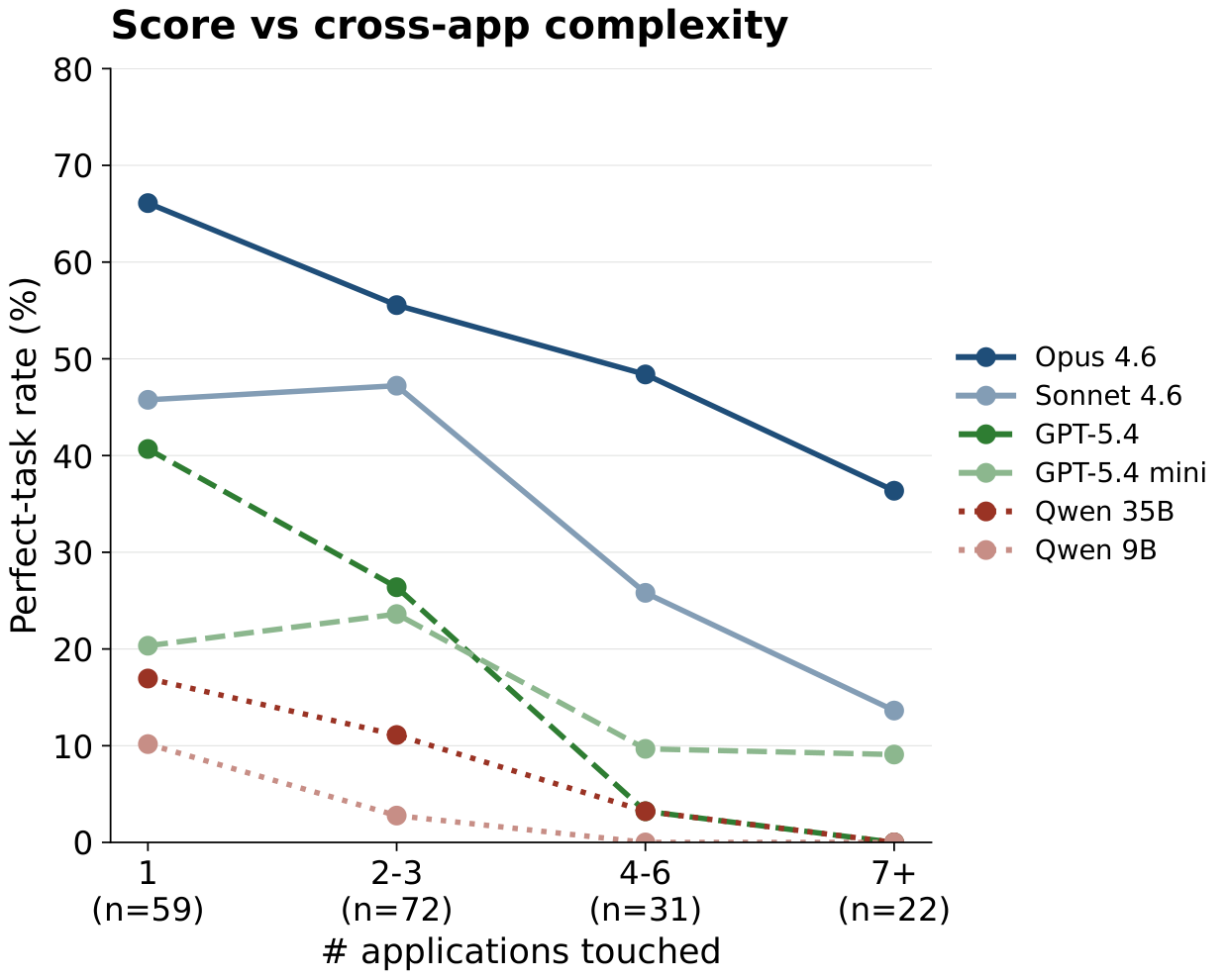
The strongest evaluated agent, Claude Opus 4.6, perfects 55.4% of MyPCBench tasks and 36% of the 7+-application slice. GPT-5.4, Qwen 3.5 35B-A3B, and Qwen 3.5 9B reach 0% perfect on the same slice.
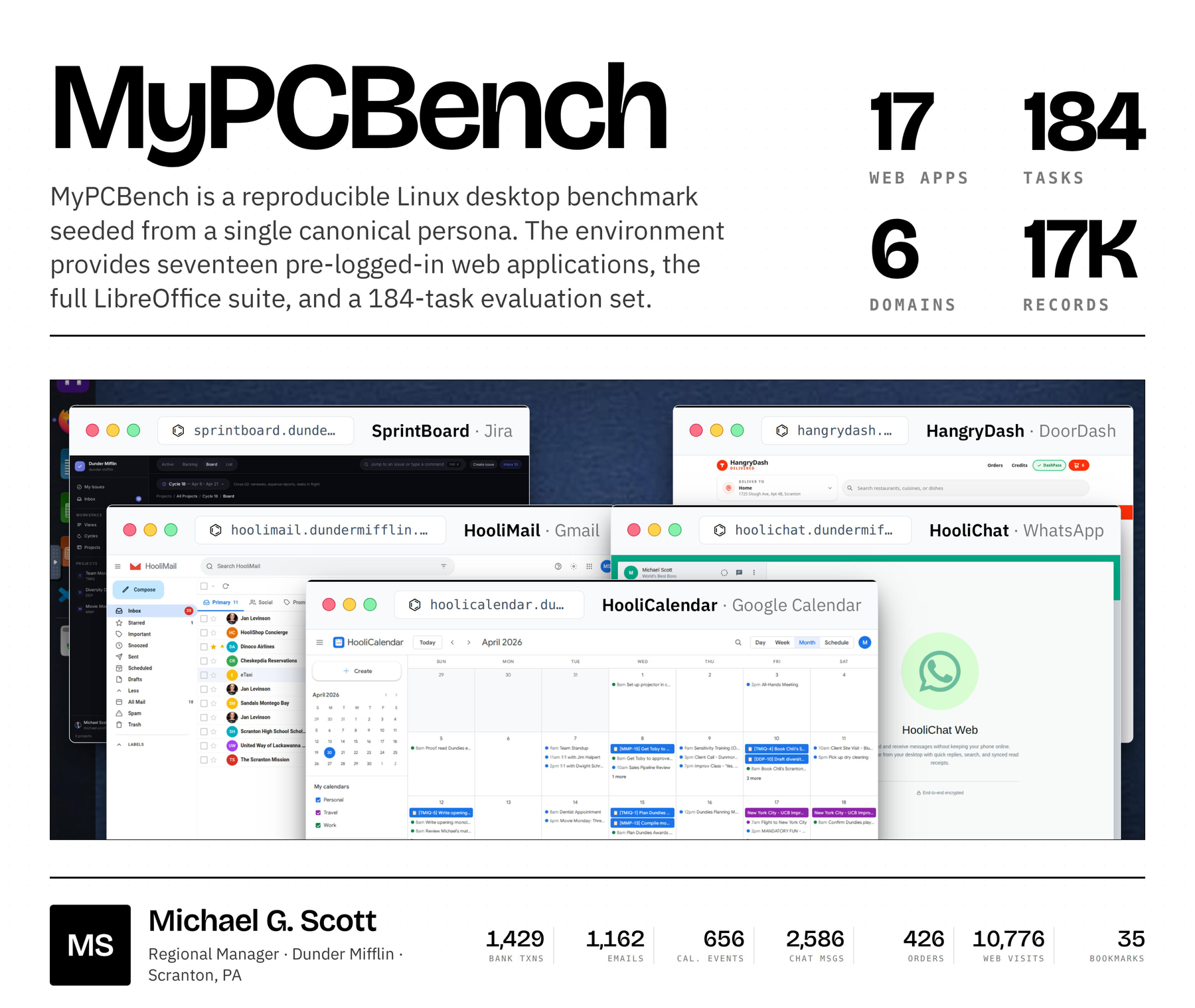
The canonical persona is Michael Scott, regional manager of a paper company in Scranton, Pennsylvania. His desktop is populated by a deterministic Python pipeline from a single JSON specification covering identity, financial profile, social network, travel history, work context, routines, preferences, and recent and upcoming life events.
Michael G. Scott
Regional Manager · Dunder Mifflin Paper Company, Scranton Branch
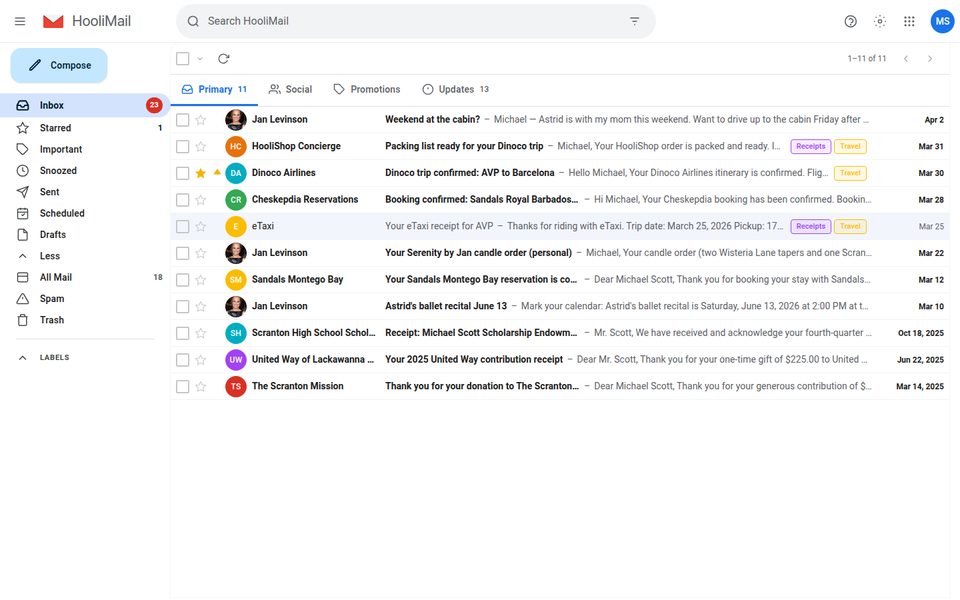
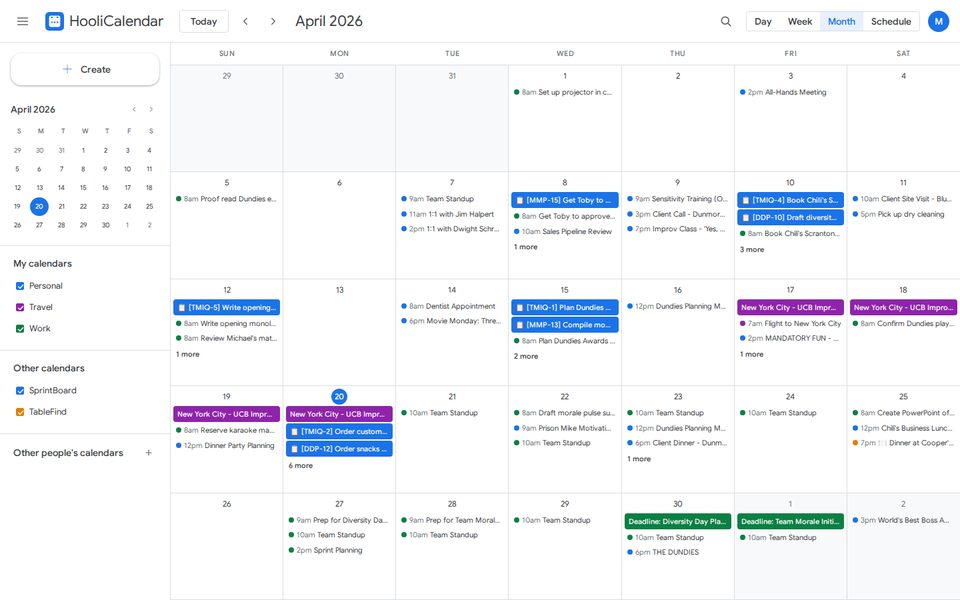
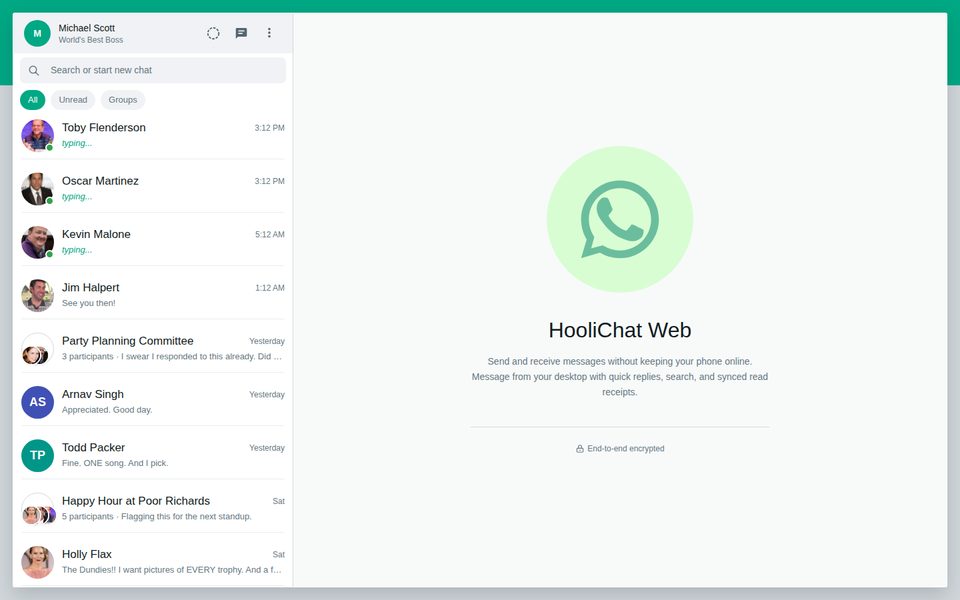
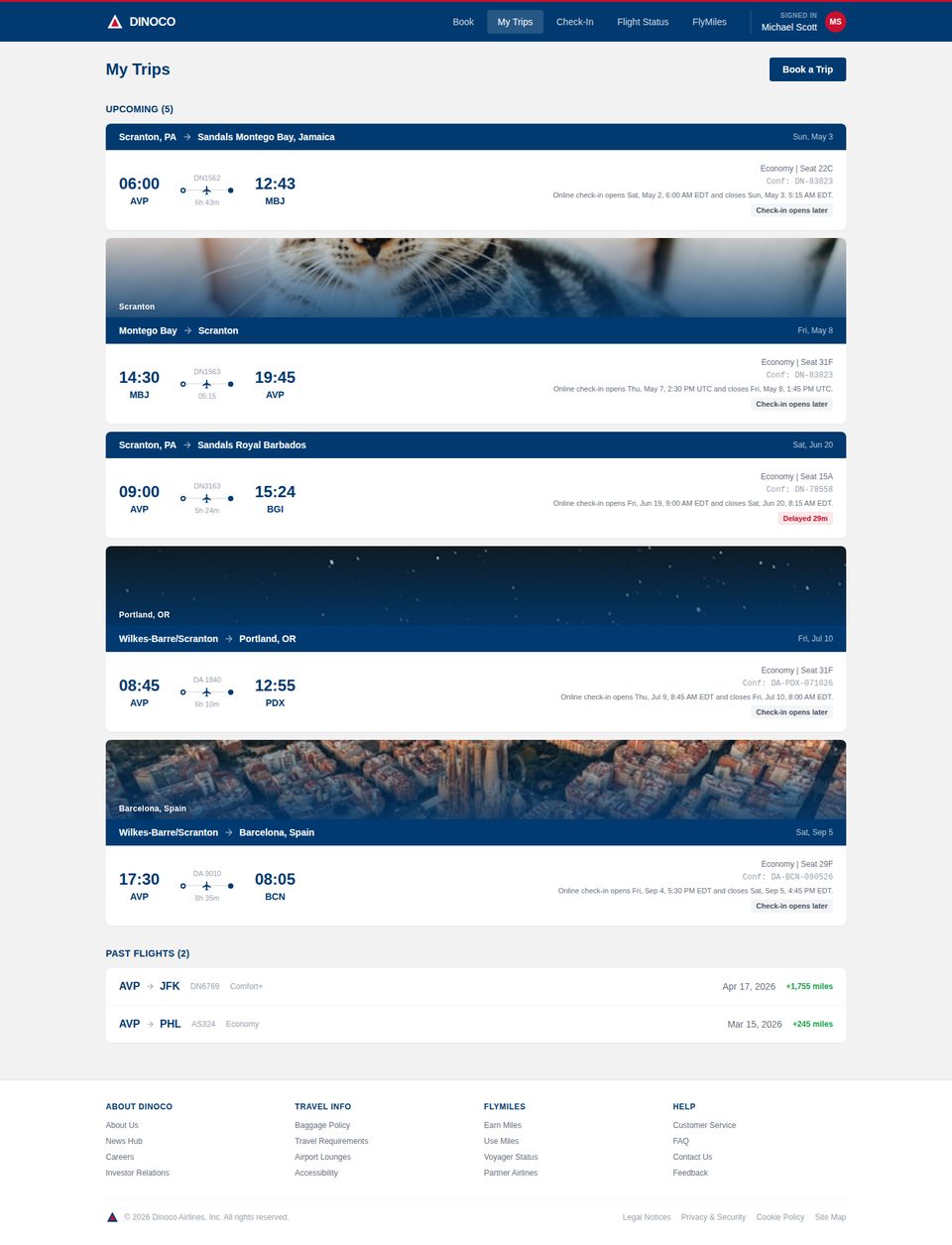
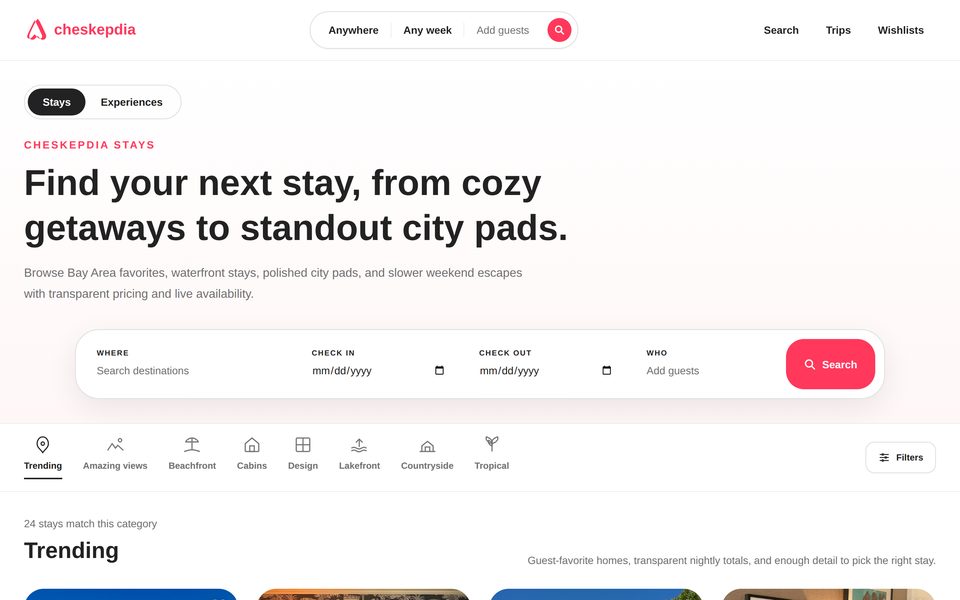
Any trip, dinner, or client deal leaves correlated records in every application that would plausibly record it. Michael's Philadelphia trip generates a Cheskepdia (Airbnb) booking, two Gringotts (Chase) charges, a HooliCalendar (Google Calendar) block, two Dinoco (Delta) boarding passes, browsing history for “Radisson Blu Warwick”, three Travel-folder emails, and HooliChat (WhatsApp) messages referencing the trip — written together at seed time so they line up at boot.
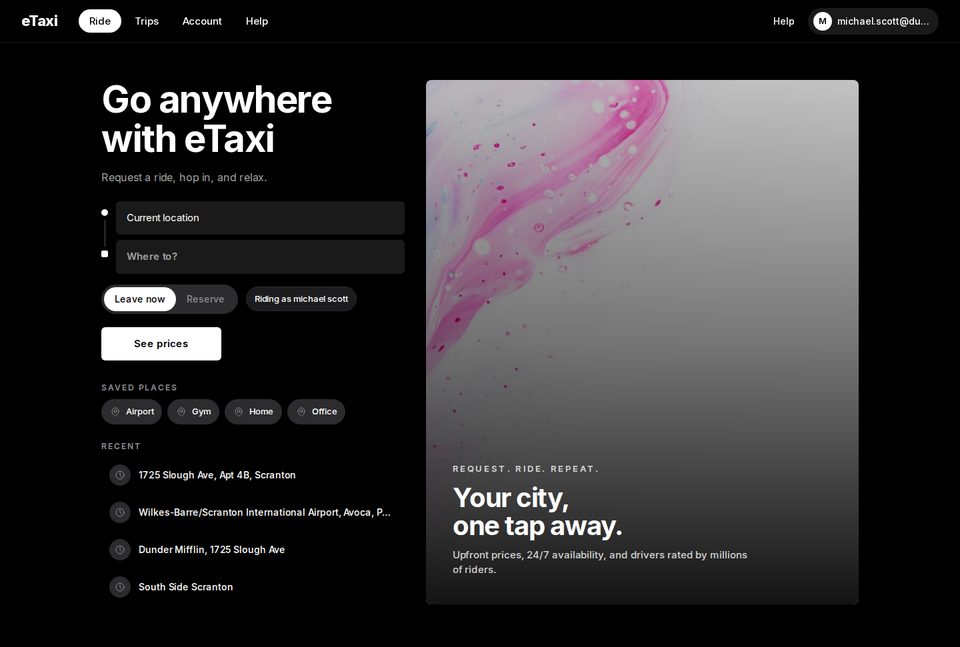
Each web application is a custom Next.js clone backed by SQLite. Gringotts supports transfers, bill pay, Zelle, and statement downloads. Dinoco Airlines generates boarding passes with QR codes. eTaxi uses OSRM for realistic routing over 700+ Scranton-area locations. TableFind exposes a reservation inventory of 3,360 slots with hold-and-release semantics. Across the canonical seed the 17 apps expose 185 distinct database tables and roughly 18,000 rows of state.

The 17 applications span six SimilarWeb top-level categories — Computers/Tech, Finance, Travel, Food, Ecommerce, Gambling — and 14 distinct subcategories. Each is a full Next.js application backed by SQLite, deterministically populated from the persona specification.
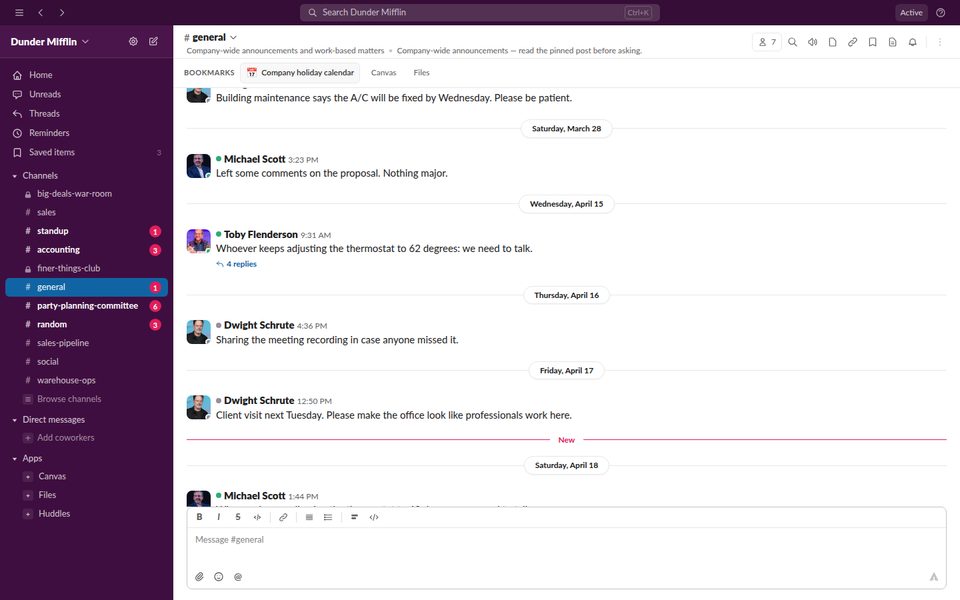
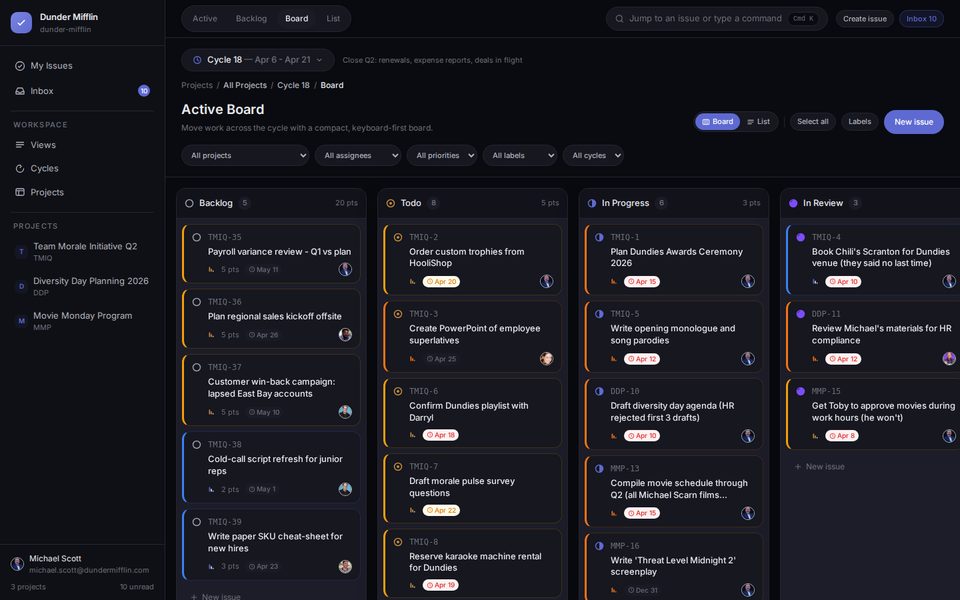

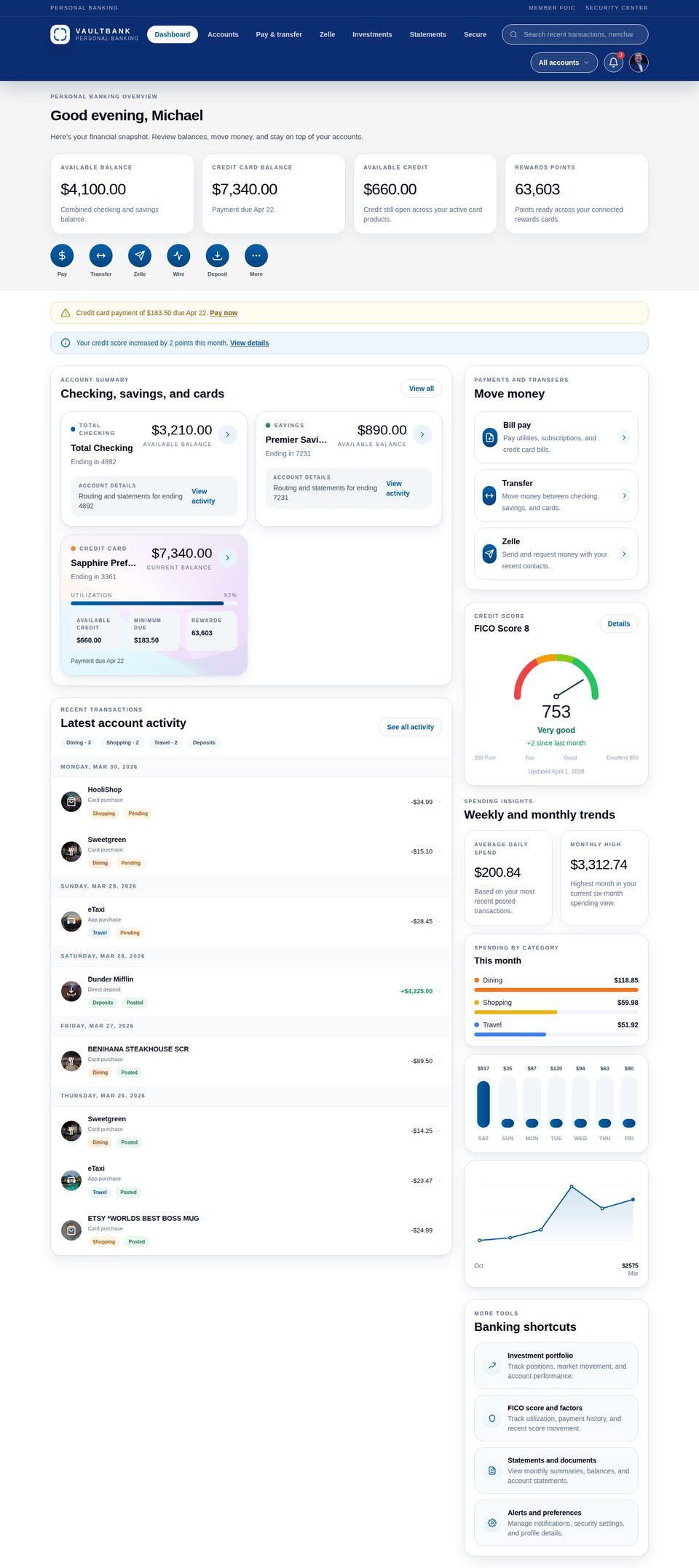
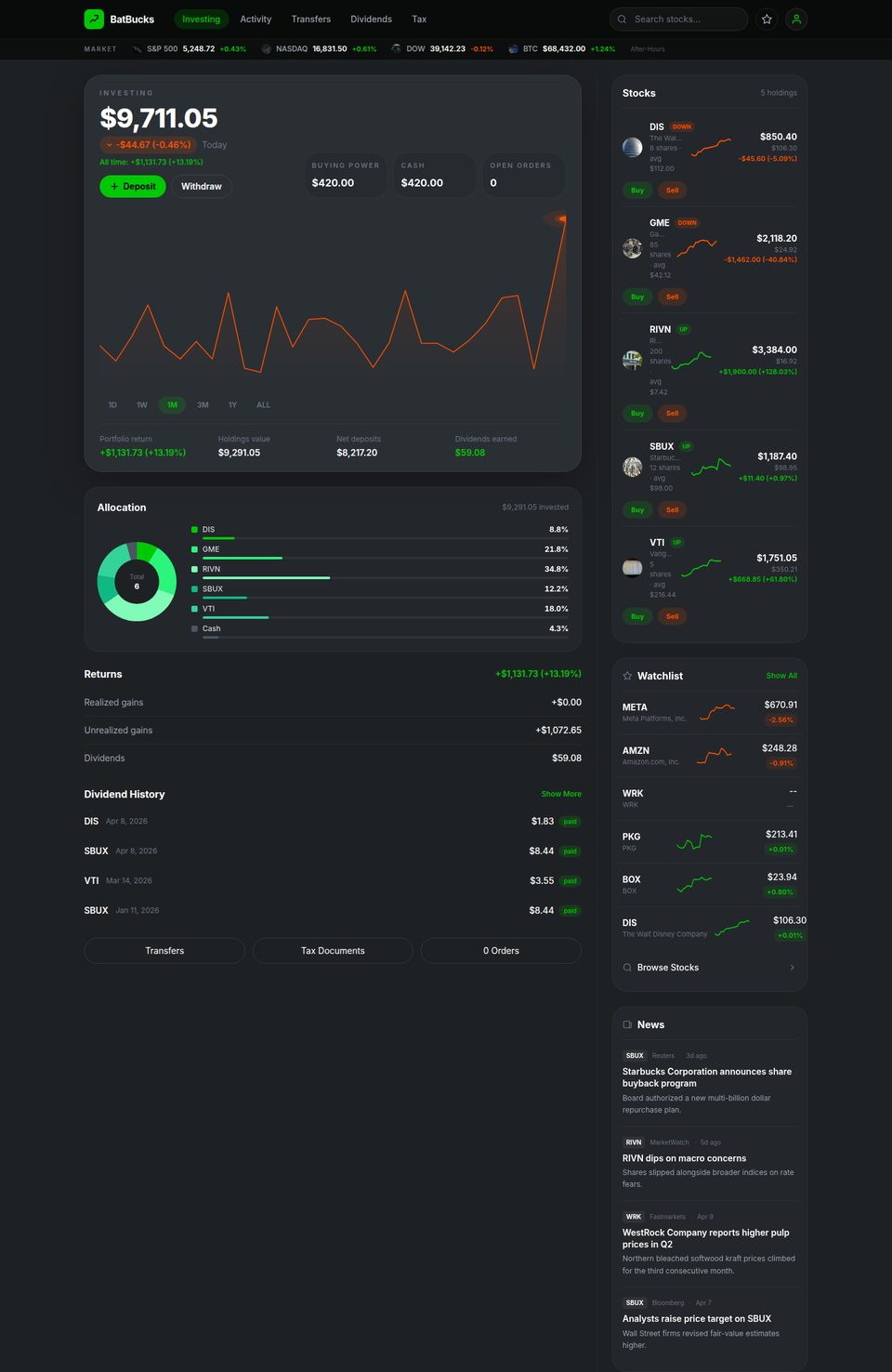

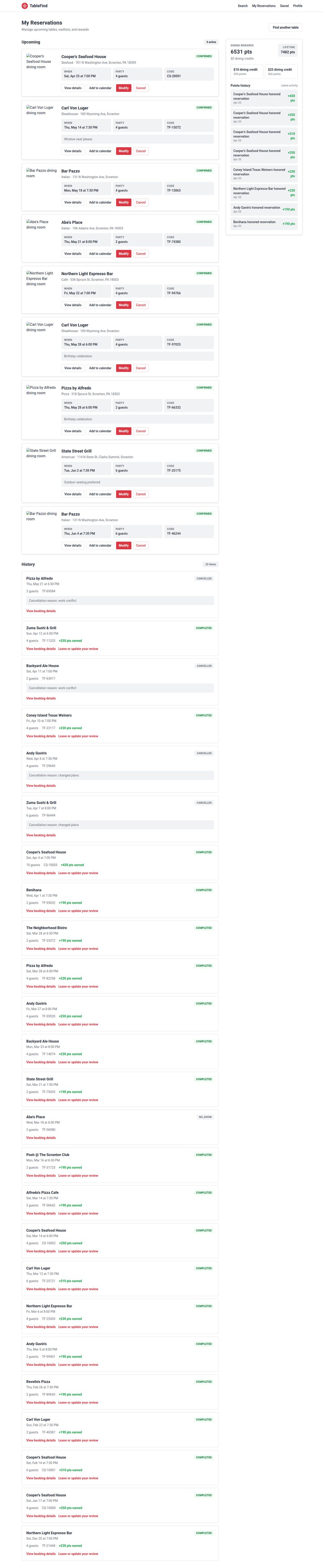
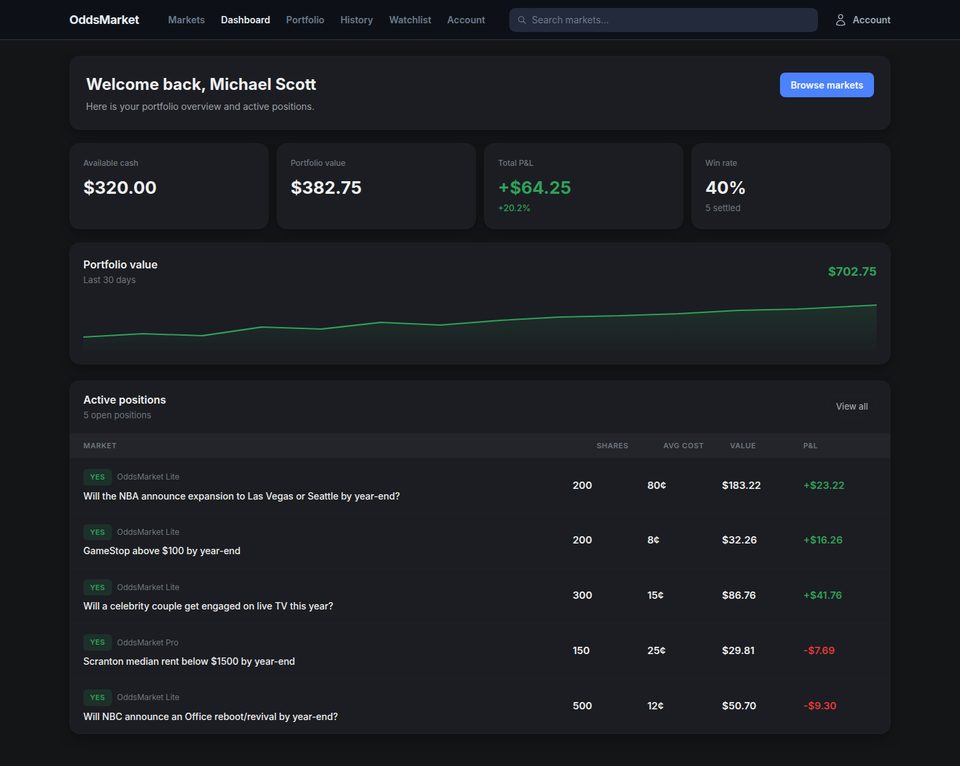
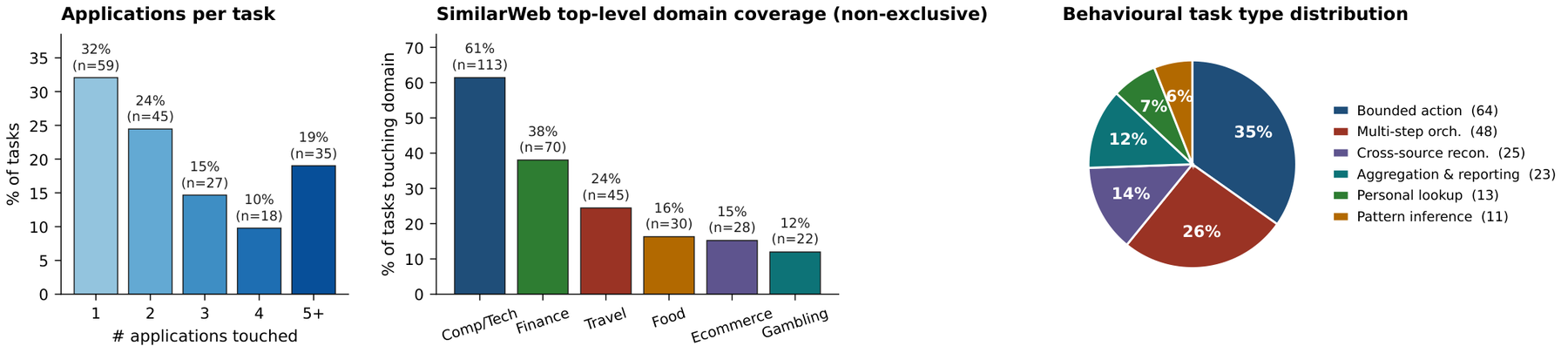
Tasks span from one to nineteen co-touched applications; 68% are multi-application and 40% span at least two SimilarWeb top-level categories. The behavioural taxonomy separates analysis tasks (lookup, aggregation, inference, reconciliation; 72 tasks) from action tasks (bounded versus orchestrated; 112 tasks).
| Type | # Tasks | Representative instruction |
|---|---|---|
| Bounded action | 64 (35%) | “Zelle Pam a hundred bucks. She covered me last weekend. Check HooliChat first to make sure Pam Beesly is on my contacts, then put a memo on the transfer.” |
| Multi-step orchestration | 48 (26%) | “The Threat Level Midnight Fan Club has been dormant. Peek at the group chat, scroll my LockedIn contacts for Dunder Mifflin folks to recruit, draft them an invitation email, and book a watch party on my calendar for next month.” |
| Cross-source reconciliation | 25 (14%) | “I've got the Jamaica trip AND the Barbados trip booked about four weeks apart. Given my credit-card balance, can I actually afford both, or am I about to max out?” |
| Aggregation & reporting | 23 (12%) | “How much am I sending via Zelle each month, and who's getting the money? Check the most recent two complete calendar months and rank the recipients in a LibreOffice Calc spreadsheet.” |
| Personal lookup | 13 (7%) | “What's my current FlyMiles loyalty tier on Dinoco Airlines, and how many miles do I have in the bank?” |
| Pattern inference | 11 (6%) | “What do I usually tip on food delivery, in dollars and as a percent? I want to set a smart default so I'm not thinking about it every order.” |
The benchmark is designed for cross-application consistency, deterministic reproducibility, and real-world UI fidelity. The harness is a thin extension of the OSWorld runner, and grading uses a rubric-by-rubric LLM-as-a-judge over the full trajectory.
The benchmark ships as a Docker image that runs a real QEMU/KVM Ubuntu 24.04 VM with GNOME Shell. The VM hosts 17 pre-logged-in websites, the full LibreOffice suite (Writer, Calc, Impress), and a Firefox profile pre-loaded with realistic browsing history and bookmarks. HooliWork (Slack) and HooliChat (WhatsApp) are exposed as native desktop apps. Boot-to-ready is ~90 seconds; a base snapshot is captured after first boot and used to reset between tasks, avoiding state leakage.
We model the environment as a partially observable MDP. At each step the agent receives a 1280×800 screenshot of the full Linux desktop plus its running tool-call history, and emits an action that the harness executes through the OSWorld VNC bridge. The action space is the unmodified OSWorld pyautogui surface (click, type, key, scroll, drag, wait, screenshot, done, fail). Provider-native CUA APIs are mapped onto this surface through a unified translation layer.
Every task ships with its own set of rubrics — natural-language criteria authored alongside the task and audited during the QA pass. Rubrics range from 3 to 13 items, with a mean of 6.5 per task and 1,191 rubric items in total. The judge runs once per rubric over the full trajectory: task instruction, that one rubric, the agent's complete tool-call log, and every screenshot. The judge returns “success” or “failure” for that item. We use gemini-3.1-flash-lite-preview as the judge throughout.
Six models evaluated under each provider's native CUA agent. Every run uses a 100-step budget, the shared persona-and-environment context, and the same Gemini judge.
Loading leaderboard…
Rubric-score percentages, models × the nine task categories. Darker = higher score.
Twelve curated trajectories, two per model, sampled across the behavioural categories. The viewer steps through the agent's screen-by-screen actions; the rubric checklist on the right transitions at the step the judge cited as evidence, and the cumulative weighted score updates accordingly.
Loading trajectories…
Keyboard · SPACE play / pause · ←/→ step · HOME / END jump · ESC close
We read every failed-rubric judge explanation and tagged it with up to five categories. Skipped required apps and premature DONE account for most of the loss. Per-family signatures: GPT concentrates in early termination, Qwen in persona-data hallucination, and Claude in console-script shortcuts that hit app REST endpoints rather than driving the visible UI.
Mean step count on zero-score trajectories splits the families the same way: GPT-5.4 (17.7), GPT-5.4 mini (19.7), and Sonnet (29.7) abandon early, while Opus (52.1), Qwen 35B (52.6), and Qwen 9B (39.2) keep going until they hit the step budget.
If MyPCBench is useful in your research, please cite the paper.
@misc{jang2026mypcbench,
title = {{MyPCBench}: A Benchmark for Personally Intelligent Computer-Use Agents},
author = {Jang, Lawrence Keunho and Jang, Andrew Keunwoo and Koh, Jing Yu and Salakhutdinov, Ruslan},
year = {2026}
}